In previous posts we’ve been talking about MLOPS and providing some details about the architecture to deploy ML models with SageMaker. In this post we are going to cover the details to deploy our model, some topics associated with classification algorithms, publish an inference endpoint and make some API calls to make predictions.
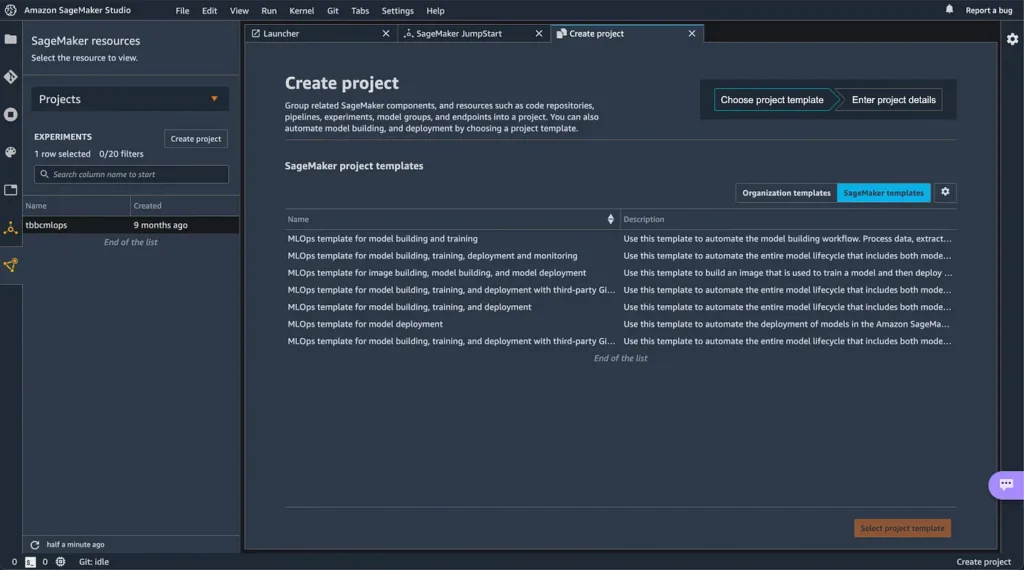
Let’s start by opening the SageMaker Studio and create a new project. As you can see in Image 1, AWS provides a couple of templates for MLOPS, for this tutorial we are going to work with the option 3: MLOps template for model building, training, deployment and monitoring.
Image 1. SageMaker Studio — Create new Project
When you choose the template, SageMaker will help you to create all the resources required to train, test, deploy and monitor your model. Two new repositories will be generated in AWS code-commit, one for model building and another for model-deploy.
So, lets take a look to the model-build project:
Image 2. Model build project structure
Our idea is to deploy a classification algorithm. After many attempts I think the XGBoost algorithm is the solution for my classification problem, so lets recap some key elements (scripts) of the MLOPS project:
Evaluate.py
Preprocess.py
Pipeline.py
The evaluate.py file helps to define, collect the model metrics and evaluate the performance of our solution, these metrics are:
Recall
Precision
ROC AUC (Area under the ROC Curve)
Image 3. Classification model metrics
The preprocess.py file allows us to apply the feature engineering step, the idea behind this is to play with the data and pick the key features to train our model or even generate new ones from other features. Then the data is splitted (you should take a look to the stratified sampling technique) into the train, validation and test sets. This information is persisted in your SageMaker Instance.
The pipeline.py file is the place where you define the steps to process data, train, test and deploy your model. There are a couple of examples most of them related to linear regressors but let’s see what you can do with a classification problem:
As you can see in Image 4, we are using the XGBOOST algorithm provided by AWS, The hyperparameter objetive is set to “binary:logistic” (applies logistic regression for binary classification).
Image 4. Model definition SageMaker Pipeline
In Image 5 you see a conditional that was added to check if the precision metric is less than 1, this is because I would verify a couple of times whether I have a model that performs perfectly for one metric. You must remember that tree of the most important metrics for binary classification problems are Precision, Recall and ROC AUC (see the bonus content at the end of the article).
For the ROC AUC, when you have a value of 1 is because your classifier performs perfectly and when this value is 0.5 we are talking about a pure random classifier. There is also a concept called precision vs recall trade off , this means that if you increase one of these metrics the another one is going to decrease.
Note: take a look to your data or your model if you obtain a value equal to 1.
Image 5. Conditional step to register the model after evaluating the precision metric
Finally we register all the steps in our pipeline:
Process: split the data into train, validation and test sets.
Train: train your model with the train and validation sets
Evaluation: evaluation of your model with the test set
Conditional step to register a new model and continue with the deployment of your staging endpoint
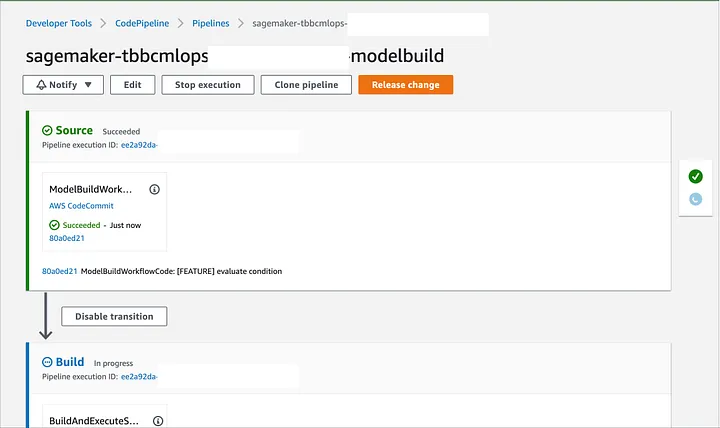
To deploy your changes you just need to commit your changes or click the button release change from AWS CodePipeline (Image 6), then you will see the process to train, validate and test your model from CodePipeline and the SageMaker dashboard.
Image 6. CodePipeline model build pipeline execution
If you want to check, just go to SageMaker and take a look for every step of the Pipeline in detail.
Image 7. SageMaker Dashboard — Model Build Process
When the model has been registered we can deploy the inference endpoint. Just take a look to the model deploy project that includes a CloudFormation template to create the infrastructure required to deploy a SageMaker Endpoint.
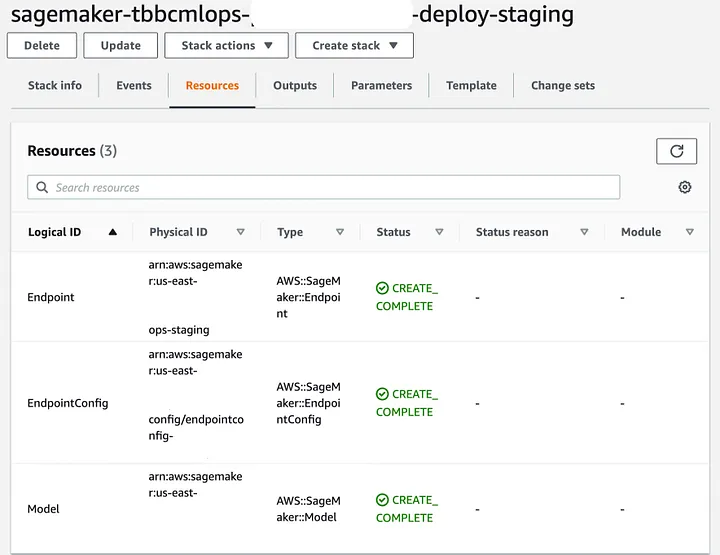
In CloudFormation (Image 8) you will see a couple of elements:
The SageMaker model you built in the code-build step
Endpoint config and the instance associated to it
Image 8. SageMaker Endpoint CloudFormation
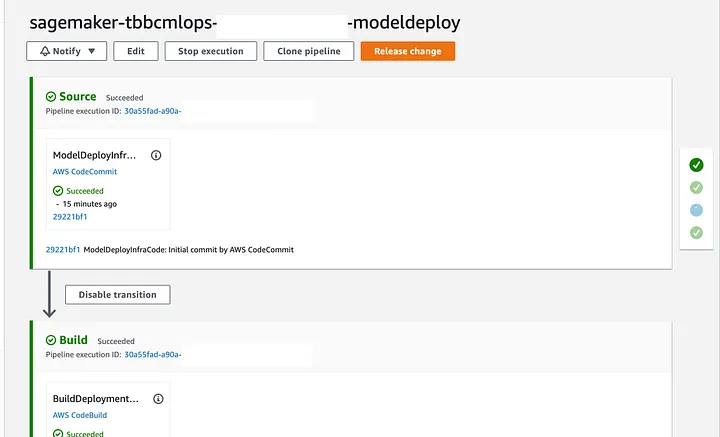
The pipeline is now ready to deploy the model in staging environment and then will ask if you want to promote the changes to production environment (lets say no at this moment) we would like to test the inference endpoint in staging environment.
Image 9. SageMaker model deploy pipeline steps — part 1
Image 10. SageMaker model deploy pipeline steps — part 2
When AWS CodePipeline is executing the TestStaging step, SageMaker obtains the metrics defined. If your model doesn’t perform well during the training process this step fail because your model is not a good candidate for production environment.
As a result, we see a new inference endpoint in service:
Image 11. In Service Endpoints SageMaker
Finally your endpoint (Image 12) has been deployed, you can check the details and obviously you are good to go with some API calls.
Image 12. SageMaker Endpoints Detail
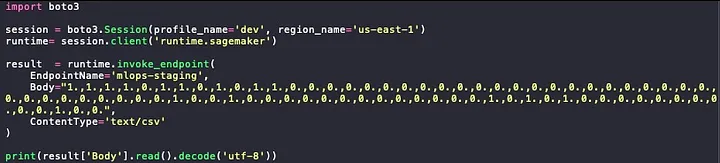
I’ve prepared a small script to test my predictions, and this is some spoiler for the next post…. I have to provide the features encoded.
Image 13. Python Script to invoke the SageMaker Endpoint
Import the boto3 library and generate a new session using your IAM credentials (Local environment).
Call the SageMaker API passing the parameters required:
The name of the endpoint in service
The record you want to classify with its information encoded
The content type, as you can see is a comma separated string so I specify it is csv
Then I print the prediction result (Image 14), as a result the classification algorithm says is 92.7% sure this record belongs to the X category.
Image 14. Execution endpoint call
Bonus:
Evaluating a classifier is often tricky and there are many performance measures you can use:
Use a confusion matrix, this is going to return
The true negatives (correctly classified as non X) — false positives (wrongly classified as X)
True positives ( wrongly classified as non X) — true positives (correctly classified as X)
Remember, there is a trade off with these metrics. If you increase one the other is going to decrease, this is called precision / recall trade — off.
The receiver operating characteristic (ROC) curve, it is a common tool for binary classifiers and plots a curve for the true positive rate (recall) vs false positive rate (FPR) or specificity.
One important measure is the Area Under the Curve (AUC) for a ROC curve:
A perfect classificatory will have a value equal to 1 (a perfect classifier)
A really bad classification algorithm have a value less or equal to 0.5 (random classifier)
I hope you enjoy this post, I am not an expert but I have curiosity to see how some things work and share with others my experiences.










Leave A Comment