Aplicando prácticas de MLOPS con SageMaker – Parte 2
Author: Esteban Ceron
Posted On: 04 de julio de 2023
Post Comments: 0
Introducción
En publicaciones anteriores hemos estado hablando sobre MLOPS y proporcionando algunos detalles sobre la arquitectura para implementar modelos de ML con SageMaker. En esta publicación vamos a cubrir los detalles para implementar nuestro modelo, algunos temas asociados con algoritmos de clasificación, publicar un punto final de inferencia y hacer algunas llamadas de API para realizar predicciones.
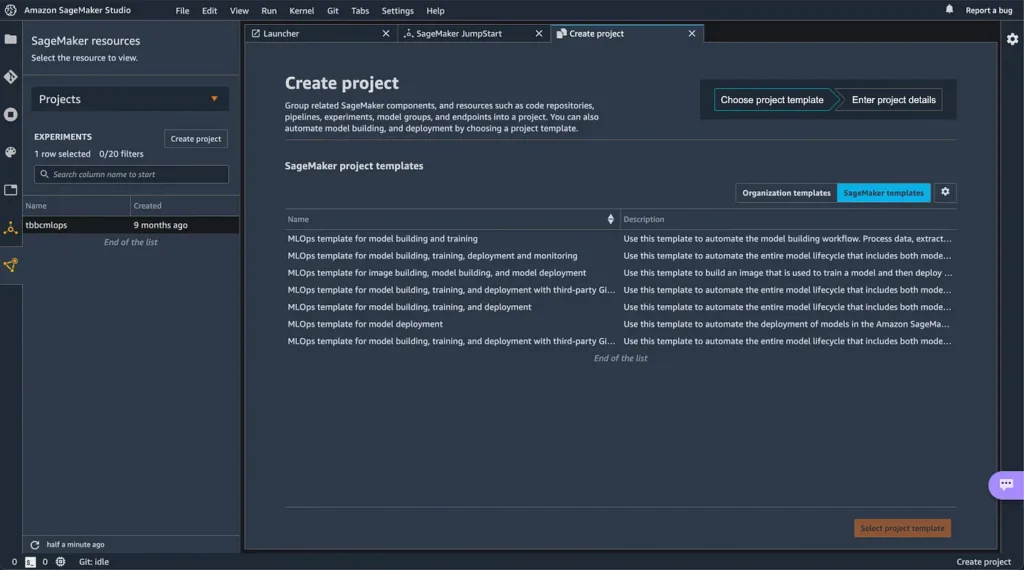
Comencemos abriendo SageMaker Studio y creando un nuevo proyecto. Como puedes ver en la Imagen 1, AWS proporciona un par de plantillas para MLOPS, para este tutorial vamos a trabajar con la opción 3: Plantilla de MLOps para construcción, entrenamiento, implementación y monitoreo de modelos.
Image 1. SageMaker Studio — Create new Project
Cuando elijas la plantilla, SageMaker te ayudará a crear todos los recursos necesarios para entrenar, probar, implementar y monitorear tu modelo. Se generarán dos nuevos repositorios en AWS CodeCommit, uno para la construcción del modelo y otro para la implementación del modelo.
Entonces, echemos un vistazo al proyecto de construcción del modelo:
Image 2. Model build project structure
Nuestra idea es implementar un algoritmo de clasificación. Después de muchos intentos, creo que el algoritmo XGBoost es la solución para mi problema de clasificación, así que repasemos algunos elementos clave (scripts) del proyecto MLOPS:
Evaluate.py
Preprocess.py
Pipeline.py
El archivo evaluate.py ayuda a definir, recopilar las métricas del modelo y evaluar el rendimiento de nuestra solución, estas métricas son:
Recall
Precisión
ROC AUC (Área bajo la curva ROC)
Image 3. Classification model metrics
El archivo preprocess.py nos permite aplicar el paso de ingeniería de características, la idea detrás de esto es jugar con los datos y seleccionar las características clave para entrenar nuestro modelo o incluso generar nuevas características a partir de otras. Luego, los datos se dividen (debes echar un vistazo a la técnica de muestreo estratificado) en conjuntos de entrenamiento, validación y prueba. Esta información se guarda en tu instancia de SageMaker.
El archivo pipeline.py es el lugar donde defines los pasos para procesar datos, entrenar, probar e implementar tu modelo. Hay un par de ejemplos, la mayoría de ellos relacionados con regresores lineales, pero veamos qué puedes hacer con un problema de clasificación:
Como puedes ver en la Imagen 4, estamos utilizando el algoritmo XGBOOST proporcionado por AWS. El hiperparámetro “objetive” se establece en “binary:logistic” (aplica regresión logística para clasificación binaria).
Image 4. Model definition SageMaker Pipeline
En la Imagen 5 se muestra una condición que se agregó para verificar si la métrica de precisión es menor que 1, esto se debe a que verifiqué un par de veces si tengo un modelo que funciona perfectamente para una métrica. Debes recordar que las métricas más importantes para problemas de clasificación binaria son la precisión, el recall y el ROC AUC (consulta el contenido adicional al final del artículo).
En cuanto al ROC AUC, cuando tienes un valor de 1 significa que tu clasificador funciona perfectamente y cuando este valor es 0.5 estamos hablando de un clasificador puramente aleatorio. También existe un concepto llamado “trade-off” entre precisión y recall, esto significa que si aumentas una de estas métricas, la otra disminuirá.
Nota: echa un vistazo a tus datos o tu modelo si obtienes un valor igual a 1.
Image 5. Conditional step to register the model after evaluating the precision metric
Finalmente, registramos todos los pasos en nuestro pipeline:
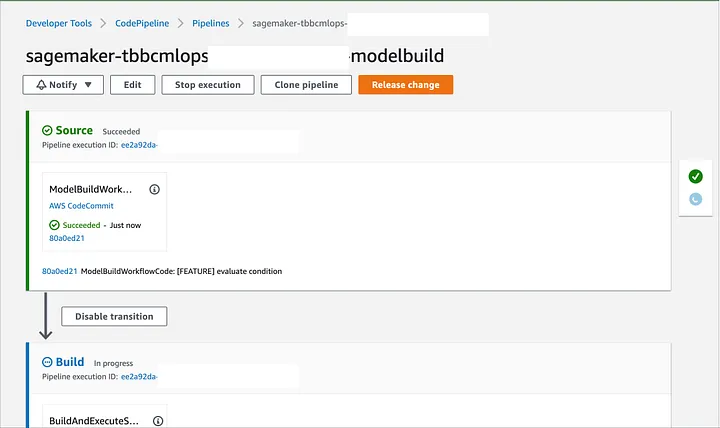
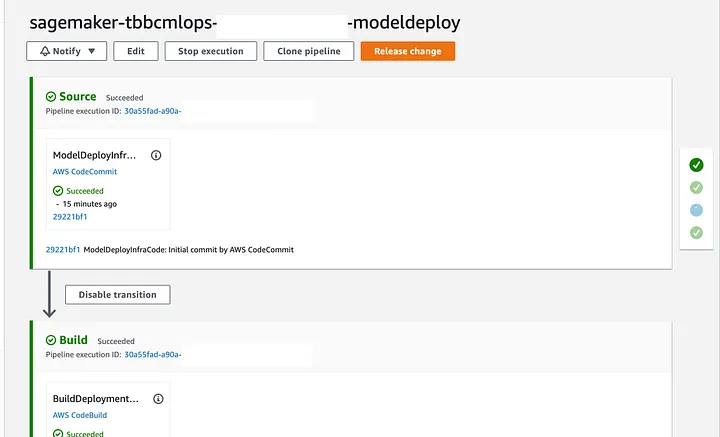
Procesamiento: dividir los datos en conjuntos de entrenamiento, validación y prueba. Entrenamiento: entrenar tu modelo con los conjuntos de entrenamiento y validación. Evaluación: evaluación de tu modelo con el conjunto de prueba. Paso condicional para registrar un nuevo modelo y continuar con la implementación de tu punto final de escenario. Para implementar tus cambios, solo necesitas confirmar tus cambios o hacer clic en el botón “Release Change” de AWS CodePipeline (Imagen 6), luego verás el proceso para entrenar, validar y probar tu modelo desde CodePipeline y el tablero de SageMaker.
Image 6. CodePipeline model build pipeline execution
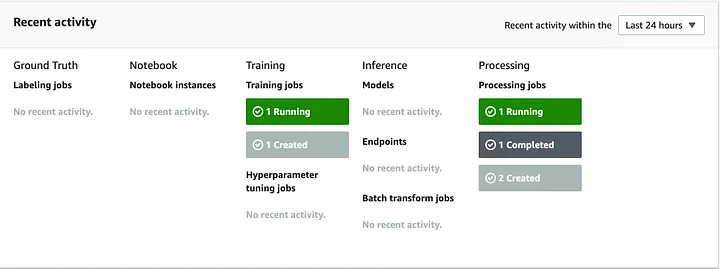
Si deseas verificarlo, simplemente ve a SageMaker y revisa cada paso del Pipeline en detalle.
Image 7. SageMaker Dashboard — Model Build Process
Cuando el modelo se haya registrado, podemos implementar el punto final de inferencia. Solo echa un vistazo al proyecto de implementación del modelo que incluye una plantilla de CloudFormation para crear la infraestructura necesaria para implementar un punto final de SageMaker.
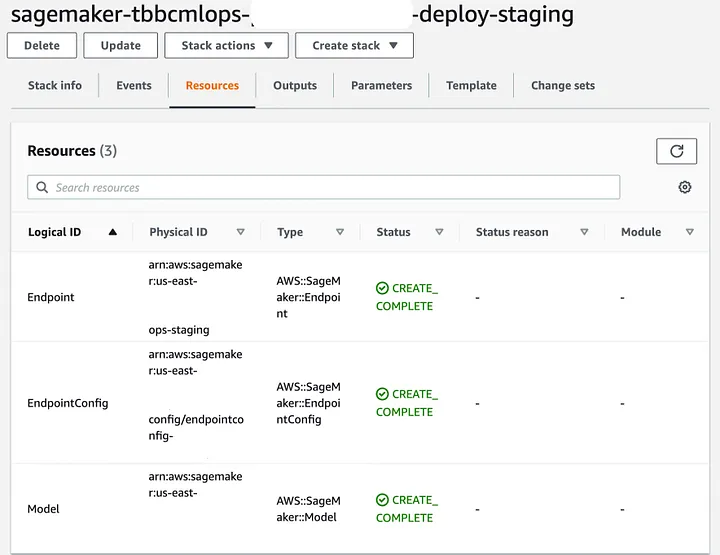
En CloudFormation (Imagen 8) verás un par de elementos:
El modelo de SageMaker que construiste en el paso de construcción del código. La configuración del punto final y la instancia asociada a él.
Image 8. SageMaker Endpoint CloudFormation
El pipeline está listo para implementar el modelo en el entorno de preparación y luego preguntará si deseas promover los cambios al entorno de producción (digamos que no en este momento), nos gustaría probar el punto final de inferencia en el entorno de preparación.
Image 9. SageMaker model deploy pipeline steps — part 1
Image 10. SageMaker model deploy pipeline steps — part 2
Cuando AWS CodePipeline está ejecutando el paso de prueba de preparación (TestStaging), SageMaker obtiene las métricas definidas. Si tu modelo no tiene un buen rendimiento durante el proceso de entrenamiento, este paso fallará porque tu modelo no es un buen candidato para el entorno de producción.
Como resultado, vemos un nuevo punto final de inferencia en servicio:
Image 11. In Service Endpoints SageMaker
Finalmente, se ha implementado tu punto final (Imagen 12), puedes verificar los detalles y, obviamente, estás listo para realizar algunas llamadas de API.
Image 12. SageMaker Endpoints Detail
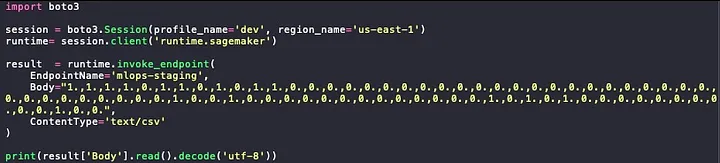
He preparado un pequeño script para probar mis predicciones, y esto es un adelanto para la próxima publicación… Tengo que proporcionar las características codificadas.
Image 13. Python Script to invoke the SageMaker Endpoint
Importa la biblioteca boto3 y genera una nueva sesión utilizando tus credenciales de IAM (entorno local).
Llama a la API de SageMaker pasando los parámetros requeridos:
El nombre del punto final en servicio.
El registro que deseas clasificar con su información codificada.
El tipo de contenido, como puedes ver, es una cadena separada por comas, así que especifico que es csv.
Luego imprimo el resultado de la predicción (Imagen 14), como resultado, el algoritmo de clasificación dice que tiene un 92.7% de certeza de que este registro pertenece a la categoría X.
Image 14. Execution endpoint call
Bonus:
Evaluar un clasificador a menudo es complicado y hay muchas medidas de rendimiento que puedes utilizar:
Utiliza una matriz de confusión, esto te dará:
Los verdaderos negativos (clasificados correctamente como no X) – falsos positivos (clasificados incorrectamente como X).
Los verdaderos positivos (clasificados incorrectamente como no X) – verdaderos positivos (clasificados correctamente como X).
Hay algunas métricas importantes:
Precisión: la precisión de las predicciones correctas.
Recuerda, hay un equilibrio con estas métricas. Si aumentas una, la otra disminuirá, esto se llama equilibrio entre precisión y recall.
La curva característica de operación del receptor (ROC), es una herramienta común para clasificadores binarios y traza una curva para la tasa de verdaderos positivos (recall) frente a la tasa de falsos positivos (FPR) o especificidad.
Una medida importante es el área bajo la curva (AUC) para una curva ROC:
Un clasificador perfecto tendrá un valor igual a 1 (un clasificador perfecto). Un algoritmo de clasificación realmente malo tiene un valor menor o igual a 0.5 (clasificador aleatorio).
Espero que disfrutes esta publicación, no soy un experto, pero tengo curiosidad por ver cómo funcionan algunas cosas y compartir con otros mis experiencias.
Para Daniel Vásquez y el equipo de TBBC, les agradezco sinceramente por su fuerte apoyo.










Leave A Comment